
De forma ampla, conceito de Engenharia Reversa aplicado a sistemas e bancos de dados, pode ser definido como: “o processo de derivar as especificações lógicas dos componentes do sistema computacional a partir de sua descrição física (código fonte e tabelas, campos e índices) com auxílio de ferramentas automatizadas”.
Migração de software e de banco de dados consiste em reescrever, por meio de refatoração ou implementação nova, todo um sistema computacional ou sistema de gerenciamento de banco de dado - SGBD, para uma tecnologia diferente.
Por fim, pode-se conceituar que sistemas computacionais legados - hardware ou, em nosso contexto, software legado, consiste em aplicações em uso e auxiliando processos empresariais, porém, de difícil manutenção, má concepção ou modelagem defasada, ou ainda implementado em tecnologia antiga ou em desuso pela empresa.
Estes são os três conceitos principais para que você entenda o que é engenharia reversa aplicada em sistemas e bancos de dados que necessitam de migração.
Antes de continuarmos no artigo, assista o vídeo a seguir. Ele apresenta a aplicação de uma ferramenta para realizar a engenharia reversa de bancos de dados relacionais, utilizando a versão open source do software cliente de Gestão de Banco de Dados chamado DBeaver
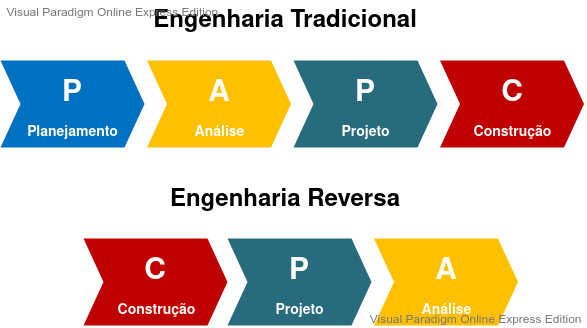
Etapas de engenharia
Simplificadamente, pode-se definir as fases da engenharia tradicional seguindo as etapas: Planejamento -> Análise -> Projeto -> Construção. Enquanto a engenharia reversa inverte estas etapas, novamente de forma simplificada, da seguinte maneira: Construção -> Projeto -> Análise.
O diagrama a seguir demonstra um comparativo entre as etapas de cada abordagem:
Entradas e Saídas da Engenharia Reversa
As entradas e saídas de cada abordagem tendem a desempenhar papéis diferentes, a seguir uma lista das entradas da engenharia reversa, que costumeiramente são produtos de saída na engenharia tradicional.
Entradas
As fontes de entrada para a aplicação de técnicas de engenharia reversa estão relacionadas ao contexto em que se está trabalhando, na lista a seguir descreve-se, principalmente, as fontes para trabalho com bancos de dados:
- Código-fonte: para os casos de realizar a engenharia reversa de uma aplicação, com o objetivo de, a partir de de seu código-fonte, obter diagramas de seus componentes, tais como: Diagramas de Classe e Diagramas de Sequência, dentre outros.
- Dicionário de dados: quando se trabalha com bancos de dados, os dicionários de dados, em geral físicos, obtidos a partir das tabelas de sistemas dos SGBD (Sistemas de Gerenciamento de Bancos de Dados). Em uma explicação simplificada, são obtidos a partir da conexão com o banco de dados do qual se deseja realizar a engenharia reversa.
São a fonte para geração de modelos físicos de dados ou mesmo modelos lógicos como MER ou IDEF1X. As diversas saídas são tratadas na sequência desta lista. - DDL - Data Definition Language: ou Linguagem de Definição de Dados, um subconjunto da SQL, seria o conjunto de comandos que descrevem as estruturas e são interpretados pelos SGBD. Mais parecido com o “código-fonte” de uma aplicação e, da mesma maneira que o dicionário de dados, são a fonte para a geração dos diversos níveis de modelos de dados.
Saídas
Tratando especificamente das saídas na aplicação de engenharia reversa em bancos de dados, podemos listar como produtos:
- Desenho do banco de dados: mostra a estrutura lógica de um banco de dados, seus relacionamentos e restrições que determinam como os dados estão estruturados.
- Estrutura física dos dados: descreve o modo como os dados são salvos em meios físicos pelo banco de dados, sendo definidos tanto os dispositivos de armazenamento físico como dos métodos de acesso (físico) necessários para se chegar aos dados nesse dispositivos, o que o torna dependente tanto de software como de hardware.
- Modelo Entidade-Relacionamento (MER): um diagrama que descreve dados, entidades e seus relacionamentos nos aspectos de informação do domínio de negócio, de uma maneira abstrata, sem a definição física de seus componentes.
- Modelo de dados normalizado: descreve as entidades, seus dados e relacionamentos, de forma a respeitar as 5 Formas Normais de Normalização de Bancos de Dados.
- Especificação do projeto: detalhes do projeto a partir dos componentes físicos do banco de dados.
Benefícios da Engenharia Reversa
Ao se deparar pela primeira vez com o termo ou orientação para executar uma engenharia reversa, é comum a estranheza em relação ao questionamento: “Mas e a documentação do projeto?”.
Infelizmente, nem todo projeto consegue manter sua documentação, atualizada ou minimamente útil.
Portanto, muitos são os contextos onde a aplicação desta técnica são benéficos.
Imagine um membro novo de equipe que necessita ter uma melhor compreensão dos sistemas, ou até mesmo, uma equipe que precisa ter uma visão ampla atualizada dos sistemas atuais.
Outra aplicação prática é a aceleração do processo de manutenção, principalmente para módulos de sistemas que passam por mudanças frequentes onde a documentação se deteriora rapidamente.
Mais um cenário relacionado a equipes é a recuperação do conhecimento sobre os sistemas, por vezes, as documentações de módulos não tratam das integrações existentes de maneira ampla.
Uma das aplicações mais comuns e úteis acontece na necessidade de migração de sistemas, principalmente se parte da equipe é nova no projeto.
Além das migrações, situações de integrações, como no caso de fusão de empresas, tornam a engenharia reversa uma prática obrigatória para análise das estratégias entre equipes.
Reestruturação
A reestruturação é o processo de padronização de nomes de dados, definições e estrutura lógica de programas e bases de dados para melhorar a manutenção e produtividade do software.
Ela tem como objetivos melhorar um programa, por meio de sua arquitetura atualizada ou melhor organização do modelo de dados, diminuir tempo de testes, garantir padrões e boas práticas de programação, simplificar e reduzir custos de manutenção e alteração e, ainda quando necessário, reduzir a dependência dos mantenedores.
Dois tipos de reestruturação podem ser definidos: de código-fonte ou lógica, e de dados.
Reestruturação de Código-fonte/lógica
Processo de análise dos fluxos de controle e lógica de programação com geração de uma versão estruturada do código-fonte original sem alteração de sua funcionalidade.
Uma grande gama de sistemas são candidatos a passarem por uma reestruturação lógica:
- Código de baixa qualidade: aqueles escritos em contexto sem análise e implementação de arquitetura ou padrões de código
- Dificuldade (impossibilidade) para ler, alterar e testar o código: aqueles desenvolvidos com estruturas e componentes que não permitem implementação de automatização de testes
- Taxa de erros, tempo de correção e custos altos: aqueles que apresentam uma frequência alta de erros e necessitam de correção constante, muito provavelmente por ter código de baixa qualidade, dificultando sua leitura e testes, tornando-se sistemas de alto custo
- Estratégicos caros e e frequentemente alterados: aqueles são de alto grau de importância para o negócio, porém por diversas situações, como força legal, concorrência, mudanças estratégicas de negócio, necessitam ser constantemente alterados.
Funções das aplicações de reestruturação
Os sistemas que fazem análise de código e estruturas de dados para reestruturação possuem uma série de funções que auxiliam nesta tarefa.
A análise de lógica e métrica avalia as estruturas do código com a finalidade de encontrar arquiteturas frágeis relacionadas a padrões e boas práticas de linguagens e frameworks, indicando então soluções de reestruturação.
A análise de dados segue uma estratégia parecida com a análise de lógica e métrica, porém aplicada às estruturas de bases de dados, procurando indicar melhores práticas arquiteturais nos modelos dos relacionamentos.
Além das análises citadas, estas aplicações ainda realizam:
- limpeza da linguagem, visando eliminar comandos não recomendados ou utilizados fora dos padrões,
- limpeza do código, eliminando código morto, loops infinitos e lógica confusa
Reestruturação de dados
Falando especificamente da reestruturação de bases de dados, podemos conceituar como o processo de eliminação de redundância de nomes de dados e de adoção de padrões.
Muitos benefícios são obtidos por meio da reestruturação de dados, dentre eles a criação de uma base de dados normalizada e estável seria um dos mais impactantes.
Isto permite uma melhor base para integração entre sistemas de informação, por meio da utilização de nomes de dados padronizados e a melhoria da consistência e do significado dos dados.
Tal qual os sistemas, uma gama de bases de dados são candidatas a reestruturação de dados, listados a seguir:
- Definições de dados inconsistentes: aquelas bases onde as estruturas foram construídas sem a consistência obtida com a aplicação de normalização, no caso de bancos de dados relacionais; alta redundância de metadados, ou ainda, relacionamento entre estruturas de maneira conceitualmente equivocada
- Nome de dados não padronizados: aquelas que não seguem um glossário padronizado de termos, baseado em nomenclaturas adequadas corretamente ao negócio, ou ainda, dados com o mesmo conceito nomeados de maneira diferente entre as entidades
Funções das aplicações de reestruturação de dados
Os sistemas que fazem análise de estruturas de dados e seus relacionamentos para reestruturação possuem uma série de funções que auxiliam nesta tarefa.
A função de análise de dados, como já citada no parágrafo da seção anterior, segue uma estratégia parecida com a análise de lógica e métrica, avalia as estruturas do entidades e dados, com a finalidade de encontrar arquiteturas frágeis relacionadas a padrões e boas práticas.
A função de verificação da normalização das estruturas, tabelas e relacionamentos, com o objetivo de encontrar falha nas regras de normalização de modelos de bancos de dados relacionais, ao menos a a 3a (terceira) forma normal.
A função de preservação dos dados atuais, com o intuito de analisar se alterações de estruturas podem levar a perda de dados. Ou ainda, criar uma estratégia de preservação histórica de dados, principalmente quando é necessário aplicar alteração de contextos em dados. Por exemplo: separar colunas de nome em primeiro nome e sobrenome.
Por fim a função de padronização de nome semi-automática, baseada em parametrizações, alterar os nomes das estruturas, tabelas, campos, relacionamentos, índices, chaves, com o intuito de obter um padrão de nomenclatura para facilitar a comunicação de todos envolvidos de equipes técnicas que trabalham com as bases de dados.
Migração de bancos de dados e softwares legados
Em engenharia de software, migração é um termo que pode ser empregado com diferentes nuances dependendo do contexto, porém, em geral, é a ação ou processo de realizar mudança tecnológica em ativos de sistemas legados existentes.
Por exemplo, migrar toda a lógica de um software em plataforma Delphi Desktop para PHP + framework Laravel + VueJS para Web.
Ainda neste exemplo, uma análise na tecnologia e estrutura do sistema gerenciador de banco de dados (SGBD) e sua estrutura pode resultar em algumas decisões:
1 - manter SGBD e as estruturas de dados pois continuam atendendo às regras de negócio,
2 - migrar a tecnologia mantendo a estrutura de dados, talvez SQL Server para PostgreSQL,
3 - manter a tecnologia e migrar a estrutura do modelo, talvez para adequar as melhorias nas regras de negócio que serão implantadas na migração do software, ou por fim,
4 - migrar tanto tecnologia quanto estrutura pelos motivos citados anteriormente.
Porém, migrar softwares legados é uma tarefa difícil e complexa.
Projetos de grande porte de software são complexos de se gerenciar sua manutenção. Por vezes não existem especificações de requisitos que levaram ao estado atual da aplicação, ou a documentação técnica do projeto se existente está desatualizada.
Esta complexidade os torna tanto necessários de passar por migração, quanto de alta complexidade para a execução desta atividade.
Desta maneira, não é incomum encontrarmos equipes que assumem a insegurança em iniciar projetos de migração de sistemas e, desta forma, acabam por protelar o quanto podem.
Passos para correta migração de softwares e bancos de dados
Para minimizar a insegurança das equipes, e também os riscos que qualquer migração trás, podemos seguir alguns passos para que os projetos desta natureza obtenham altos níveis de sucesso.
Conhecer detalhadamente as funcionalidades do sistema atual é o primeiro deles, em paralelo deve-se escrever a documentação necessária no formato de requisitos, como se estivesse realizando o levantamento pela primeira vez.
Utilize ferramentas de engenharia reversa para enxergar as integrações, relacionamentos e modelos de dados e componentes do sistrema atual.
Organizar os dados do sistema atual de tal forma que seja possível identificar todos os contextos do modelo de dados, relacionados às especificações de requisitos que você escreveu no primeiro passo.
Iniciar a migração somente dos dados, ou somente realizar ela.
Esta é uma estratégia que garante a atualização tecnológica do SGBD de forma tal a garantir que o ativo mais precioso dos usuários não seja perdido: a informação do negócio contida nas suas bases de dados.
Executar a migração dos componentes menos complexos do sistema, como scripts, pequenos sistemas satélite, ou mesmo pontos ou módulos possíveis de serem isolados como relatórios.
Evoluir as funcionalidades e extensões no novo sistema, desta maneira a medida que melhora o atendimento ao negócio com o software, você vai realizando a migração de pontos chave da aplicação.
Um exemplo, construir uma API de acesso à funcionalidades do sistema para iniciar a migração de um software desktop para web, iniciando pelas telas de consulta de dados.
Por fim, porém para ser executado juntamente com todas estas etapas, implemente testes evolutivamente ara garantir cada funcionalidade sendo migrada.
Benefícios do uso de engenharia reversa na migração de sistemas legados e bancos de dados
Apesar de ser um processo geralmente complexo, realizar a migração de sistemas de software e mecanismos de banco de dados traz diversos benefícios às soluções de sistemas:
- Preservação de esforços de desenvolvimento: ao utilizar técnicas de engenharia reversa na migração de sistemas e bancos de dados obtém um excelente grau de redução ou preservação de esforços de desenvolvimento, primeiramente por conseguir demonstrar rapidamente as integrações entre componentes de software e também sua estrutura arquitetural.
Quanto aos bancos de dados, permite que, mesmo que não ocorram refatorações nos modelos de dados, os desenvolvedores obtenham rapidamente uma visão de como os dados interagem entre si, os seus contextos e como ou por quê são tratados com determinadas estratégias no código-fonte - Preservação da integração dos sistemas: a visualização dos modelos visuais de componentes de software e dados também permite à equipe de desenvolvimento enxergar antecipadamente pontos de integração com outros sistemas, o que minimiza o risco de quebras nestas ligações nas migrações de tecnologias e bases de código de programação
- Garantia de atualização tecnológica: como já dito, legado tecnológico é uma realidade em qualquer equipe ou empresa que desenvolve software por alguns anos, buscar técnicas e estratégias de migração de tecnologia nos momentos corretos, com produtividade e qualidade, pode trazer a garantia necessária de se manter atualizado tecnologicamente
- Facilitação na manutenção de software: principalmente para sistemas de porte médio a grande, desenvolvido por muitos profissionais diferentes, a manutenção da documentação é complexa e difícil.
Sendo assim, aplicar técnicas de engenharia reversa auxilia nesta atualização, consequentemente, facilitando a manutenção dos softwares
Conclusões finais
Manter sistemas legados acarreta alto custo para as empresas, sendo que a decisão migração de softwares e bancos de dados é comum em equipes que irão trabalhar por anos ainda com tais sistemas.
Aplicar as técnicas e ferramentas corretas para minimizar riscos a garantir qualidade no resultado dos projetos de migração é essencial.
Sendo que as técnicas de Engenharia Reversa devem ser as primeiras a serem consideradas, analisadas e aplicadas neste processo.


Comentários