
Broadly, the concept of Reverse Engineering applied to systems and databases can be defined as: “the process of deriving the logical specifications of computer system components from their physical description (source code and tables, fields and indexes) with the help of automated tools”.
Software and database migration consists of rewriting, through refactoring or new implementation, an entire computer system or database management system - DBMS, to a different technology.
Finally, it can be conceptualized that legacy computer systems - hardware or, in our context, legacy software, consists of applications in use and helping business processes, however, difficult to maintain, poor design or outdated modeling, or even implemented in old technology. or in disuse by the company.
These are the three main concepts for you to understand what reverse engineering is applied to systems and databases that need migration.
Before continuing with the article, watch the following video. It presents the application of a tool to reverse engineer relational databases, using the open source version of the Database Management client software called DBeaver
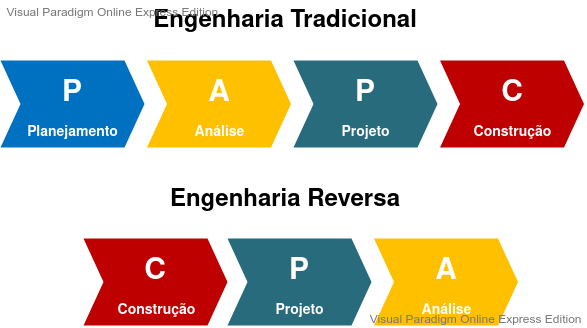
Engineering steps
Simply put, the phases of traditional engineering can be defined following the steps: Planning -> Analysis -> Design -> Construction. While reverse engineering reverses these steps, again in a simplified way, as follows: Construction -> Design -> Analysis.
The following diagram demonstrates a comparison between the steps of each approach:
Reverse Engineering Inputs and Outputs
The inputs and outputs of each approach tend to play different roles, the following is a list of reverse engineering inputs, which are typically outputs in traditional engineering.
Inputs
The input sources for the application of reverse engineering techniques are related to the context in which one is working, the following list mainly describes the sources for working with databases:
- Source code: for cases of reverse engineering an application, in order to obtain diagrams of its components from its source code, such as: Class Diagrams and Sequence Diagrams, among others.
- Data dictionary: when working with databases, data dictionaries, generally physical ones, obtained from DBMS (Database Management Systems) system tables. In a simplified explanation, they are obtained from the connection with the database that you want to reverse engineer. They are the source for generating physical data models or even logical models such as MER or IDEF1X. The different outputs are dealt with in the sequence of this list.
- DDL - Data Definition Language: or Data Definition Language, a subset of SQL, would be the set of commands that describe the structures and are interpreted by the DBMS. More like the “source code” of an application and, like the data dictionary, they are the source for generating the various levels of data models.
Outputs
Addressing specifically the outputs in the application of reverse engineering in databases, we can list as products:
- Database Design: Shows the logical structure of a database, its relationships and constraints that determine how the data is structured.
- Physical schema structure: describes the way data is saved on physical media by the database, defining both the physical storage devices and the (physical) access methods necessary to reach the data on these devices , which makes it dependent on both software and hardware.
- Entity-Relationship Model (ERM): a diagram that describes data, entities and their relationships in the information aspects of the business domain, in an abstract way, without the physical definition of their components.
- Normalized data model: describes the entities, their data and relationships, in order to respect the 5 Normal Forms of Database Normalization.
- Project Specification: Project details from the physical components of the database.
Benefits of Reverse Engineering
When first encountering the term or the indication to perform reverse engineering, it is common to be strange about the question: “But what about the project documentation?”.
Unfortunately, not every project manages to keep its documentation up-to-date or minimally useful.
Therefore, there are many contexts where the application of this technique is beneficial.
Imagine a new team member who needs to have a better understanding of the systems, or even a team who needs to have a broad, up-to-date view of current systems.
Another practical application is the acceleration of the maintenance process, mainly for system modules that undergo frequent changes where the documentation quickly deteriorates.
One more team-related scenario is the retrieval of knowledge about systems, sometimes module documentation does not address existing integrations broadly.
One of the most common and useful applications is the need to migrate systems, especially if part of the team is new to the project.
In addition to migrations, integration situations, as in the case of company mergers, make reverse engineering a mandatory practice for analyzing strategies between teams.
Restructuring
Restructuring is the process of standardizing data names, definitions, and the logical structure of programs and databases to improve software maintainability and productivity.
It aims to improve a program, through its updated architecture or better organization of the data model, reduce testing time, ensure standards and good programming practices, simplify and reduce maintenance and change costs and, even when necessary, reduce dependency on maintainers.
Two types of restructuring can be defined: source code or logic, and data.
Source/Logic Restructuring
Process of analysis of control flows and programming logic with generation of a structured version of the original source code without changing its functionality.
A wide range of systems are candidates for logical restructuring:
- Poor quality code: those written in context without parsing and implementing architecture or code patterns
- Difficult (impossibility) to read, change and test code: those developed with frameworks and components that do not allow implementation of test automation
- Error rate, correction time and high costs: those that present a high frequency of errors and need constant correction, most likely because they have low quality code, making it difficult to read and test, becoming systems of high cost
- Expensive and frequently changed strategies: those are of high importance to the business, but due to different situations, such as legal force, competition, strategic business changes, they need to be constantly changed.
Functions of restructuring applications
Systems that analyze code and data structures for restructuring have a series of functions that help in this task.
The logic and metric analysis evaluates the code structures in order to find fragile architectures related to patterns and good practices of languages and frameworks, then indicating restructuring solutions.
Data analysis follows a strategy similar to logic and metric analysis, but applied to database structures, seeking to indicate best architectural practices in relationship models.
In addition to the aforementioned analyses, these applications also perform:
- language cleaning, aiming to eliminate commands not recommended or used outside the standards,
- code cleanup, eliminating dead code, infinite loops and confusing logic
Data restructuring
Speaking specifically of database restructuring, we can conceptualize it as the process of eliminating redundancy in data names and adopting standards.
Many benefits are obtained through data restructuring, among them the creation of a normalized and stable database would be one of the most impactful.
This allows for a better basis for integration between information systems, through the use of standardized data names and improvement of data consistency and meaning.
Like systems, a range of databases are candidates for data restructuring, listed below:
- Inconsistent data definitions: those bases where the structures were built without the consistency obtained with the application of normalization, in the case of relational databases; high metadata redundancy, or still, relationship between structures in a conceptually wrong way
- Non-standard data name: those that do not follow a standardized glossary of terms, based on nomenclature correctly suited to the business, or even data with the same concept named differently between entities
Functions of data restructuring applications
Systems that analyze data structures and their relationships for restructuring have a number of functions that help in this task.
The data analysis function, as already mentioned in the paragraph of the previous section, follows a strategy similar to the analysis of logic and metrics, it evaluates the structures of entities and data, in order to find fragile architectures related to patterns and good practices.
The normalization check function of structures, tables and relationships, in order to find fault in the normalization rules of relational database models, at least the 3rd (third) normal form.
The function of preserving current data, in order to analyze whether structural changes can lead to data loss. Or even, create a strategy for historical data preservation, especially when it is necessary to apply context changes in data. For example: separate first name and last name columns.
Finally, the semi-automatic name standardization function, based on parameterizations, changes the names of structures, tables, fields, relationships, indexes, keys, in order to obtain a naming standard to facilitate the communication of everyone involved in the technical teams that work with the databases.
Migration of legacy databases and software
In software engineering, migration is a term that can be used with different nuances depending on the context, however, in general, it is the action or process of carrying out technological change in existing legacy system assets.
For example, migrating all the logic of a software in Delphi Desktop platform to PHP + Laravel framework + VueJS for Web.
Still in this example, an analysis of the technology and structure of the database management system (DBMS) and its structure can result in some decisions:
1 - maintain DBMS and data structures as they continue to comply with business rules,
2 - migrate the technology keeping the data structure, maybe SQL Server to PostgreSQL,
3 - keep the technology and migrate the structure of the model, perhaps to adapt the improvements in the business rules that will be implemented in the migration of the software, or finally,
4 - migrate both technology and structure for the reasons mentioned above.
However, migrating legacy software is a difficult and complex task.
Large software projects are complex to manage their maintenance. Sometimes there are no requirements specifications that led to the current state of the application, or the technical documentation of the project, if any, is outdated.
This complexity makes them both necessary to undergo migration and high complexity for the execution of this activity.
In this way, it is not uncommon to find teams that assume the insecurity in starting systems migration projects and, in this way, end up delaying as much as they can.
Steps for correct migration of software and databases
To minimize the insecurity of the teams, and also the risks that any migration brings, we can follow some steps so that projects of this nature obtain high levels of success.
Knowing in detail the features of the current system is the first of them, in parallel you must write the necessary documentation in the requirements format, as if you were carrying out the survey for the first time.
Use reverse engineering tools to see the integrations, relationships, and data models and components of the current system.
Organize the current system data in such a way that it is possible to identify all the contexts of the data model, related to the requirements specifications you wrote in the first step.
Start the data-only migration, or just perform it.
This is a strategy that guarantees the technological updating of the DBMS in such a way as to guarantee that the most precious asset of the users is not lost: the business information contained in its databases.
Perform the migration of less complex system components, such as scripts, small satellite systems, or even points or modules that can be isolated as reports.
Evolve the functionalities and extensions in the new system, in this way, as you improve the service to the business with the software, you will carry out the migration of key points of the application.
An example, building an API to access system functionality to start the migration from desktop software to the web, starting with the data query screens.
Finally, but to run along with all these steps, implement evolutionary tests to ensure each functionality being migrated.
Benefits of using reverse engineering when migrating legacy systems and databases
Despite being a generally complex process, performing the migration of software systems and database engines brings several benefits to systems solutions:
- Preserving Development Efforts: By using reverse engineering techniques in migrating systems and databases, you get an excellent degree of reduction or preservation of development efforts, primarily by being able to quickly demonstrate the integrations between software components and as well as its architectural structure. As for databases, it allows developers to quickly obtain a view of how data interacts with each other, their contexts and how or why they are treated with certain strategies in the source code even without refactorings taking place in the data models.
- Preservation of systems integration: Visualizing the visual models of software components and data also allows the development team to see in advance points of integration with other systems, which minimizes the risk of breaking these links in technology migrations and programming code bases
- Technological update guarantee: as already said, technological legacy is a reality in any team or company that develops software for a few years, seeking techniques and technology migration strategies at the right times, with productivity and quality, can bring the necessary guarantee to keep up to date technologically
- Software Maintenance Facilitation: Especially for medium to large systems, developed by many different professionals, the maintenance of documentation is complex and difficult. Therefore, applying reverse engineering techniques helps in this update, consequently, facilitating the maintenance of the software.
Final considerations
Maintaining legacy systems entails high costs for companies, and the decision to migrate software and databases is common in teams that will work with such systems for years to come.
Applying the correct techniques and tools to minimize risks and guarantee quality in the result of migration projects is essential.
The Reverse Engineering techniques should be the first to be considered, analyzed and applied in this process.

Comments